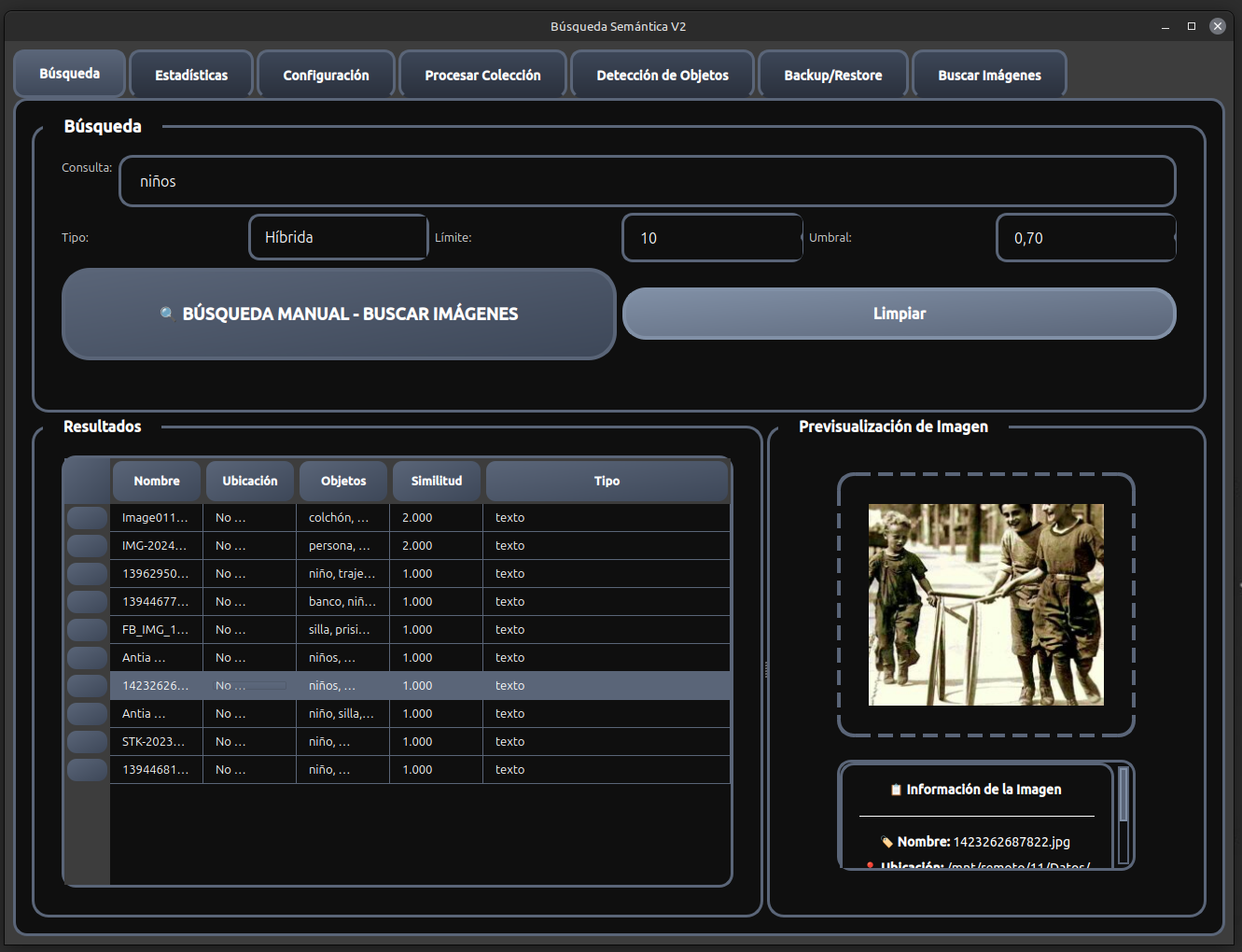
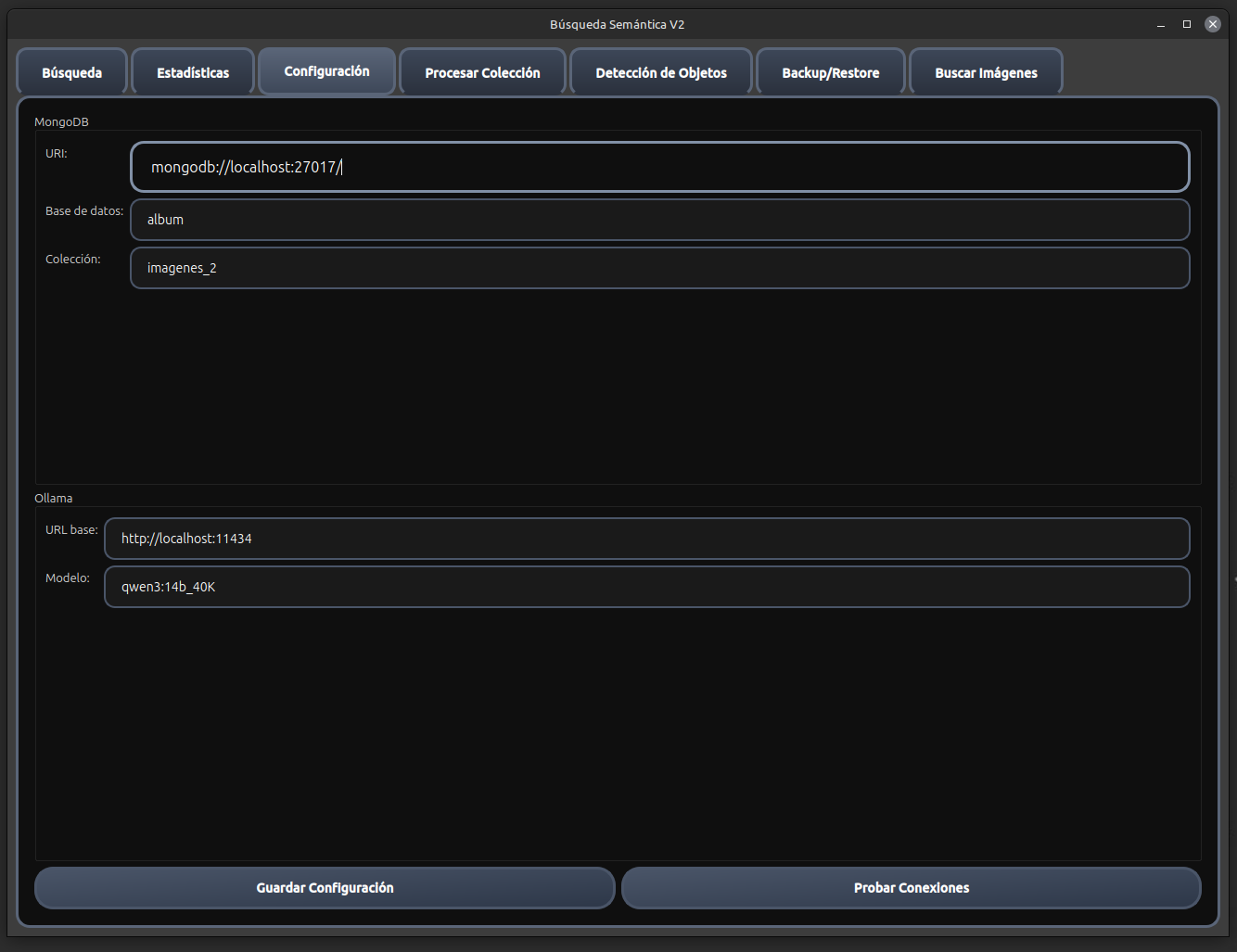
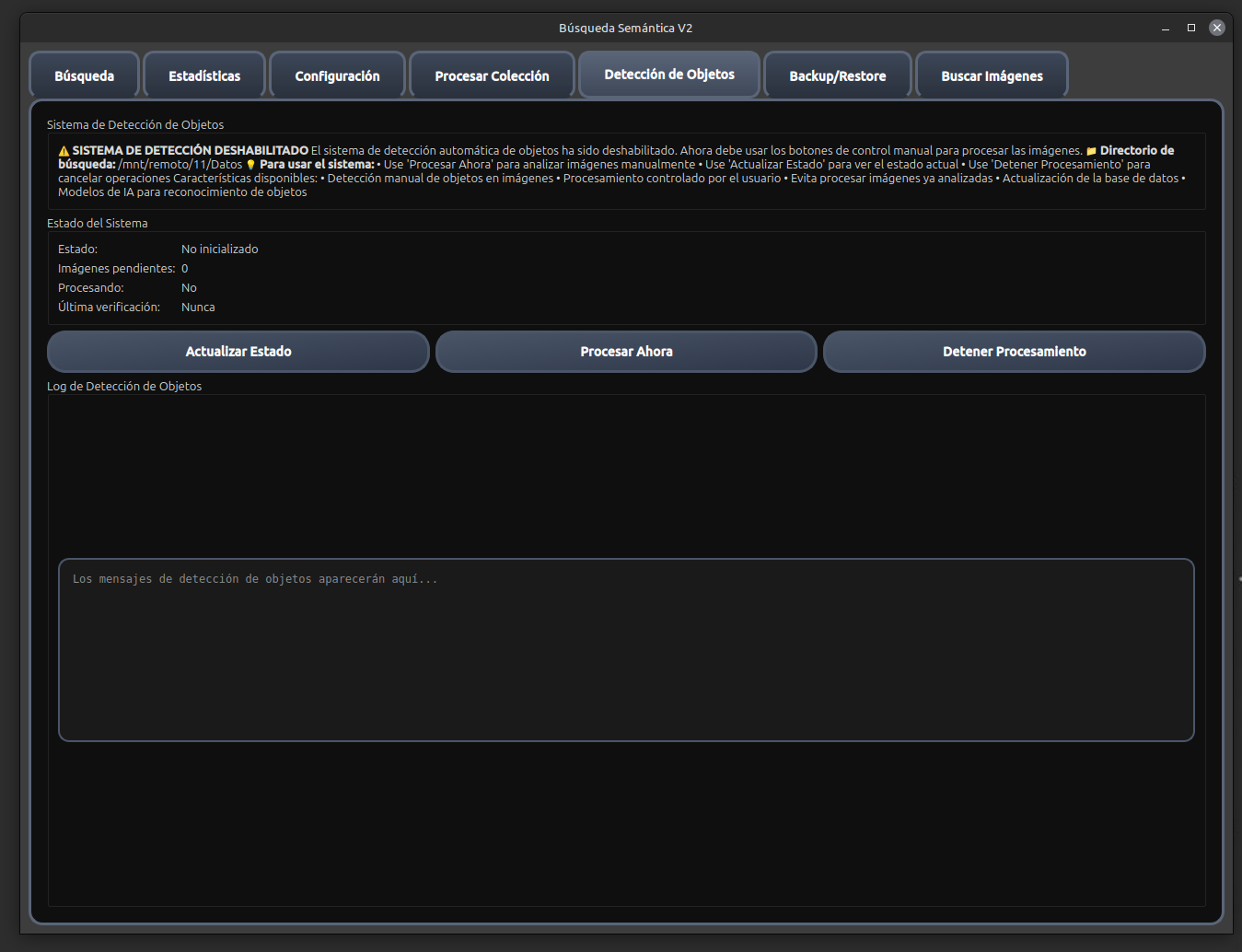
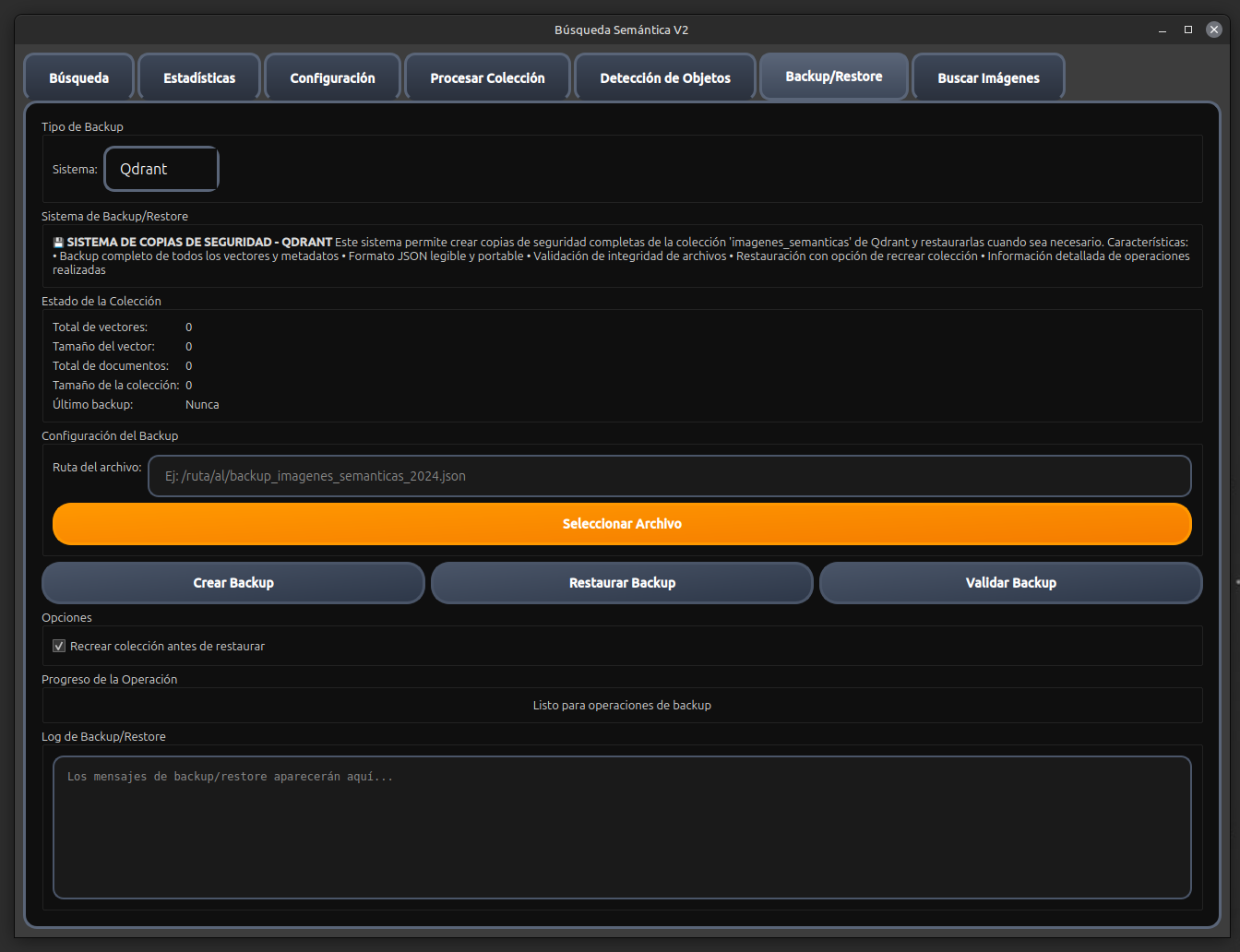
Búsqueda Semántica V2 es un sistema avanzado de búsqueda inteligente que combina múltiples tecnologías de IA para proporcionar una experiencia de búsqueda semántica superior en imágenes y documentos. El sistema utiliza modelos de lenguaje de última generación, bases de datos vectoriales y procesamiento de imágenes para ofrecer resultados de búsqueda altamente relevantes y contextuales.
¿Qué hace este sistema?
🔍 Búsqueda Semántica Inteligente
Comprende el contexto y significado de las consultas, no solo palabras clave
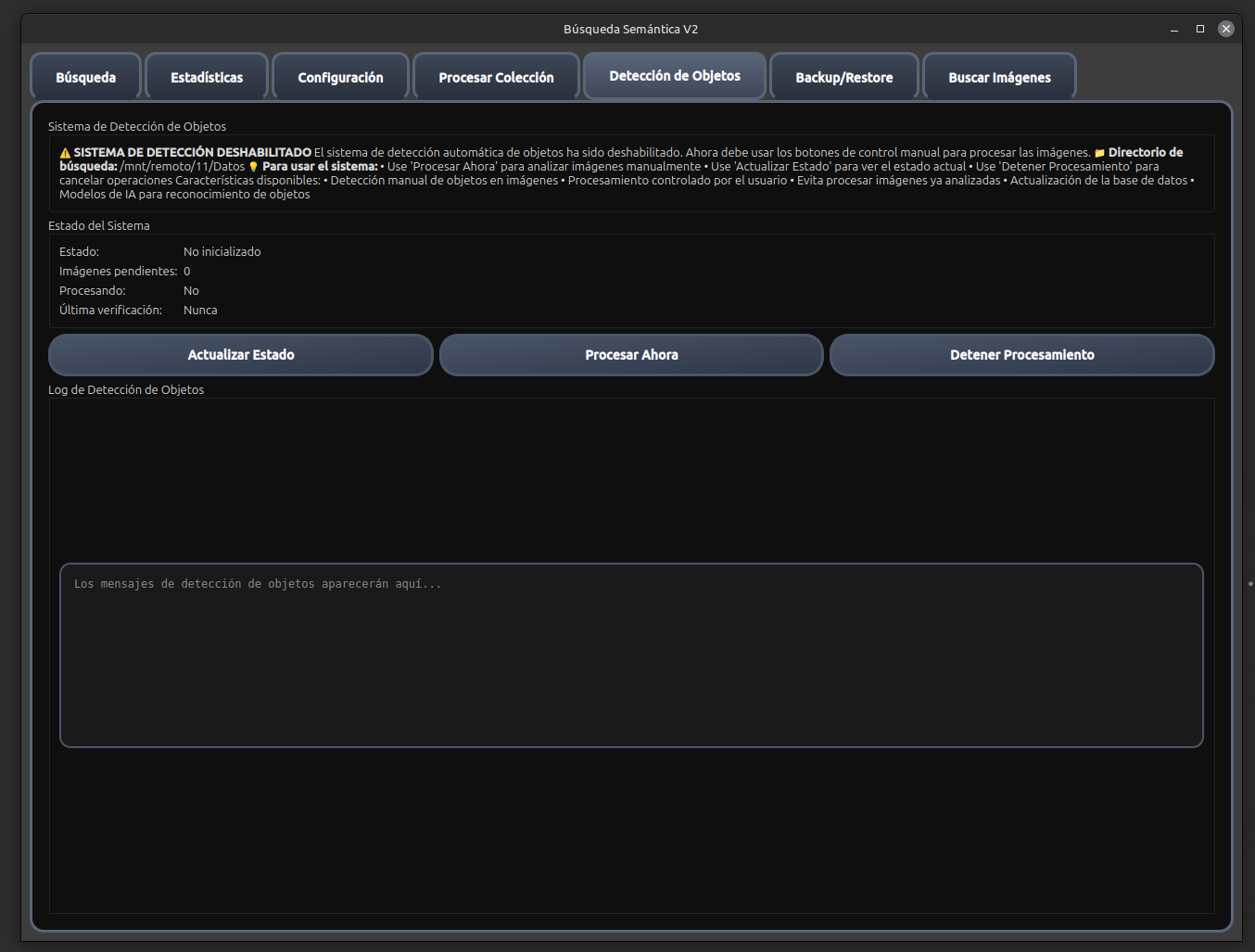
🖼️ Análisis Automático de Imágenes
Detecta objetos, personas y características en las imágenes
🔍 Búsqueda Híbrida
Combina búsqueda de texto tradicional con similitud semántica
🖥️ Interfaz Gráfica Moderna
Aplicación de escritorio intuitiva con PySide6
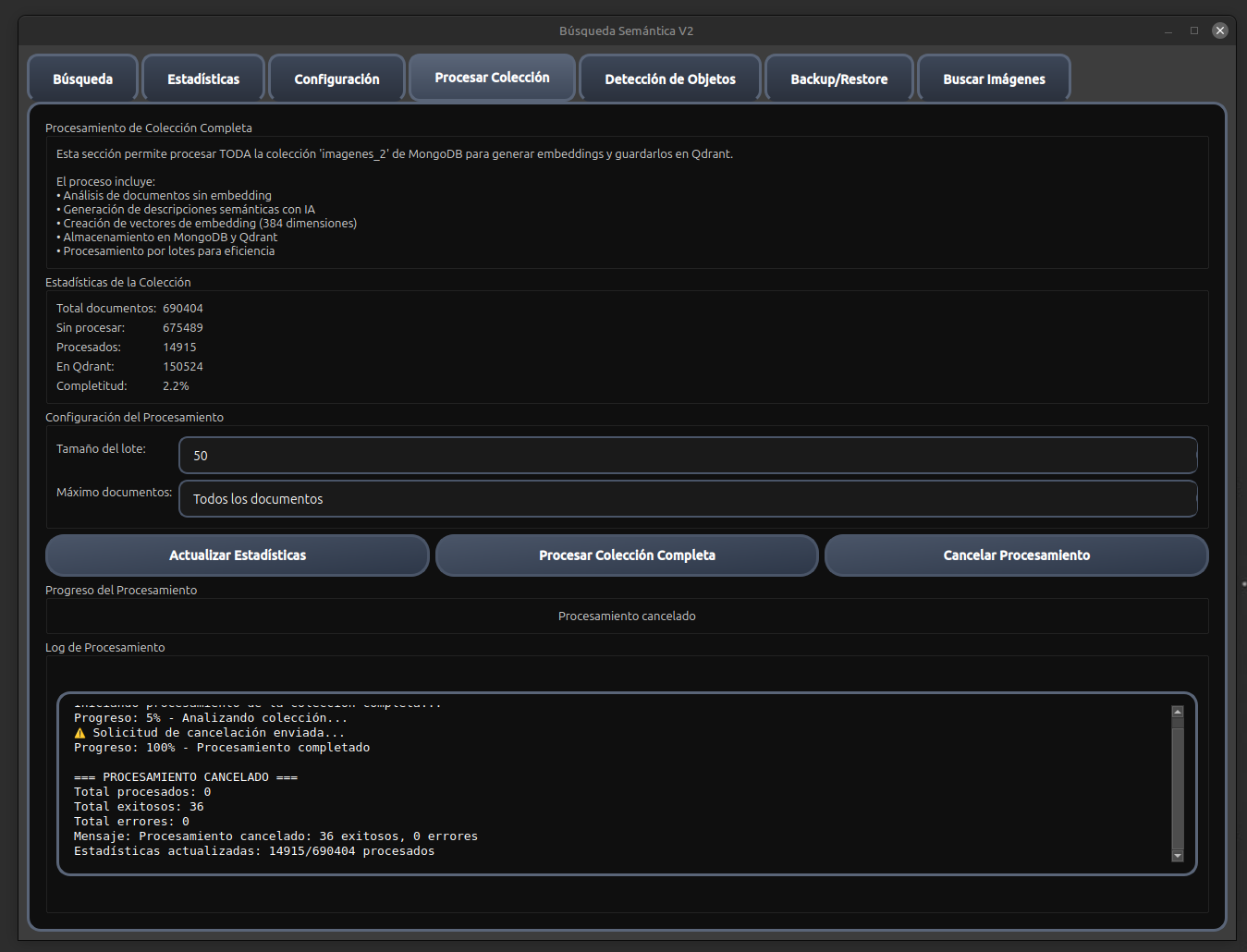
⚡ Procesamiento por Lotes
Manejo eficiente de grandes volúmenes de datos
💾 Bases de Datos Híbridas
MongoDB para almacenamiento + Qdrant para búsquedas vectoriales